


【关键词】集约化模式;机器学习;电费核算;异常;识别
引言
在电力产业领域内,电费核算作为确保电力顺畅供应、捍卫市场公正性的核心步骤,其计算的精确性和作业的高效性,对电力企业经济效益的稳定增长以及公众形象的构建起着至关重要的作用。然而,电费核算过程中受到各种因素的影响,存在一定的异常情况,不仅影响了电费核算的准确性,也给供电企业和用户带来了诸多不便。因此,对电费核算异常进行识别与处理,成为当前电费管理领域亟待解决的重要问题。现阶段,文献[1]、文献[2]提出的识别方法应用较为广泛,虽然取得了一定的成果,但是在实际应用中仍然存在缺陷。其中,李佳凝[1]提出的识别方法在面对海量复杂与动态变化的电力数据时,难以有效应对各种异常情况,导致电费核算的准确性较低。何小宇[2]等人提出的识别方法通过构建异常识别模型实现电费核算异常识别目标,存在效率低下、错误率高等问题,无法满足日益增长的业务需求。
在电力行业中,集约化模式的应用主要体现在资源的优化配置、流程的简化与标准化、管理的精细化等方面[3]。机器学习作为人工智能的核心技术之一,在电费核算异常识别中,可以自动提取与电费核算异常相关的关键特征,学习电力数据的正常模式,并自动检测与正常模式不符的异常数据,为异常识别提供有力的支持[4]。基于此,本文在集约化模式下,利用机器学习,开展了电费核算异常识别方法研究,以期为电费管理领域的可持续发展做出贡献。
一、电费核算异常识别方法设计
(一)电费核算数据采集
为了精准识别电力客户在电费核算过程中可能出现的异常情况,首要步骤是系统性地收集并深入剖析电力客户的庞大用电数据集,特别是那些直接关系到电费核算精准度的关键信息。鉴于这些数据量庞大且复杂,本文采用了精细化的数据筛选和提炼方法,将焦点锁定在负荷数据和数据采集等核心字段上,以确保分析结果的准确性和实用性。这些字段的详细信息在表1中得到了具体呈现。
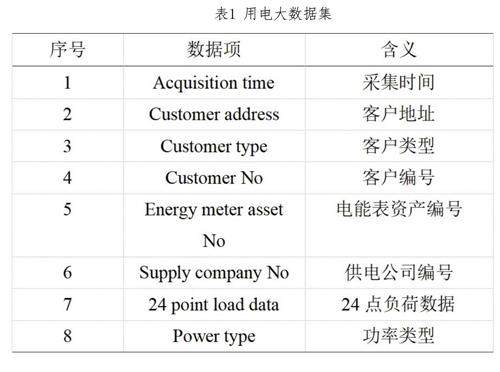
为了构建全面而精确的用电大数据集,首先从供电局的负控终端、智能电表或其他服务提供商处收集电费核算数据,包括电力客户的用电记录、账单信息、历史数据等。为了全面描绘电力使用的动态变化,将原始的日负荷数据转化为直观的日负荷曲线图。

