




人工智能离不开数据。为了训练算法以实现预期目标,我们需要大量的数据,而输入到人工智能模型中的数据质量直接决定了输出结果的优劣。然而,问题在于人工智能开发者和研究人员对所使用的数据来源了解甚少。相比于人工智能模型开发的复杂性,人工智能的数据收集实践尚不成熟,大规模数据集通常缺乏关于其内容和来源的详细信息。
为了解决这一问题,来自学术界和产业界的50多名研究人员开展了数据溯源计划。他们提出了一个简单而重要的问题:构建人工智能所需的数据究竟来自哪里?为此,他们审查了近4000个公共数据集,这些数据集涵盖了600多种语言、67个国家,并包含长达30年的数据,数据来源涉及800个不同的渠道和近700个组织。
这项研究的结果首次独家发布在《麻省理工科技评论》上,揭示了一个令人担忧的趋势:人工智能的数据实践正在使权力过度集中于少数几家主导科技公司手中。
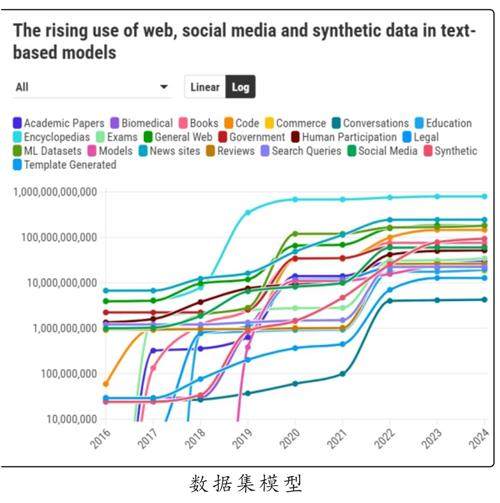
项目成员、美国麻省理工学院研究员肖恩·朗普雷表示,在十多年前,数据集的来源相对多样化,这些数据不仅来自百科全书和互联网,还包括议会记录、财报电话会议以及天气报告等来源。朗普雷指出,在那个时期,人工智能数据集是根据具体任务的需求精心策划并从不同渠道收集的。
然而,2017年,支撑大语言模型的架构——Transformer的出现,改变了这一切。随着模型和数据集规模的不断扩大,人工智能的性能显著提升。这使得人工智能领域逐渐倾向于采用更大规模的数据集。
如今,大多数人工智能数据集是通过从互联网上大规模、无差别地抓取内容构建的。自2018年起,互联网成为所有媒体类型(如音频、图像和视频)数据集的主要来源。与此同时,网络抓取的数据与更为精心策划的数据集之间的差距逐渐显现并不断扩大。
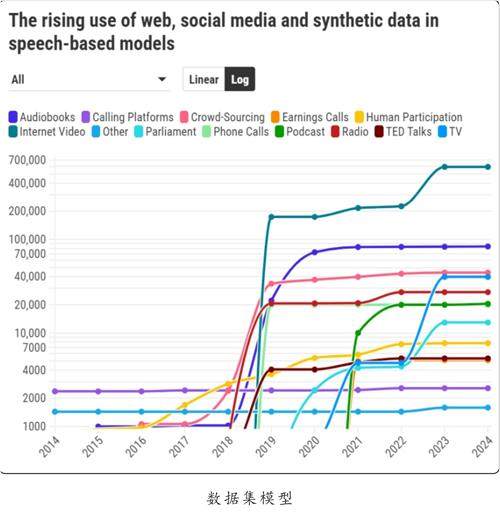
“在基础模型的开发中,数据的规模、异质性以及网络来源对模型能力的影响无与伦比。”朗普雷表示。对数据规模的需求也极大地推动了合成数据的广泛使用。
近年来,多模态生成式人工智能模型应运而生,这些模型能够生成视频和图像。与大型语言模型类似,它们需要尽可能多的数据,而目前最优的数据来源是视频平台YouTube。
以视频模型为例,从图表中可以看出,超70%的语音和图像数据集的数据都来自同一来源。
对YouTube、谷歌的母公司Alphabet来说,这可能是一个巨大的优势。与文本数据分布在众多不同的网站和平台上不同,视频数据高度集中在单一平台。
朗普雷指出:“这使得网络上一些最重要的数据的控制权高度集中在一家企业手中。”
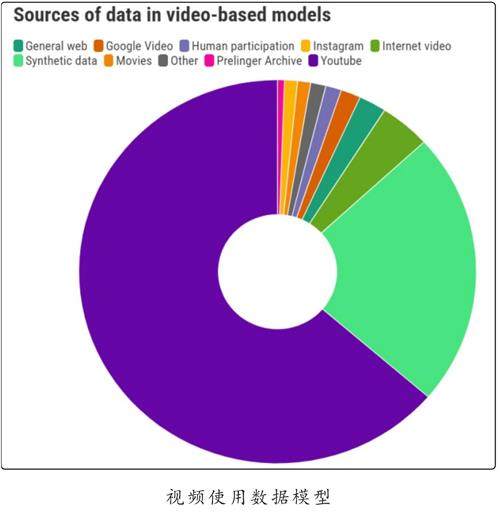
此外,谷歌自身也在开发自己的人工智能模型,这种巨大的优势引发了关于公司如何向竞争对手提供这些数据的疑问。AI Now Institute的联合执行主任莎拉·韦斯特表示,这值得进一步探讨。
她认为,我们应该将数据视为通过特定过程创造出来的东西,而不是一种自然存在的资源。
她补充道:“如果我们日常使用的大部分人工智能所依赖的数据集反映的是大公司、以利润为导向的企业的意图和设计,那么这将以符合这些大企业利益的方式重塑我们的世界基础设施。”
这种单一化也引发了关于数据集是否能够准确反映人类体验以及我们正在构建何种模型的疑问。
Cohere公司的研究副总裁、“数据源倡仪”成员萨拉·胡克表示:“人们上传到YouTube的视频通常是针对特定受众而制作的,视频中的行为往往带有特定的目的性。”她还问道:“这些数据是否捕捉到了人类存在的所有细微差别和多样性?”
隐藏的限制
人工智能公司通常不会公开用于训练模型的数据来源。一方面,这是为了保护其竞争优势;另一方面,由于数据集的打包和分发过程复杂且不透明,人工智能公司自身也可能无法完全了解所有数据的具体来源。
此外,人工智能公司可能不了解这些数据在使用或共享时所受到的限制。“数据源倡仪”的研究人员发现,许多数据集附带有严格的许可条款或使用条件,例如,可能限制其在商业用途上的应用。
“数据来源缺乏一致性,使得开发者很难正确选择使用的数据。”胡克表示。
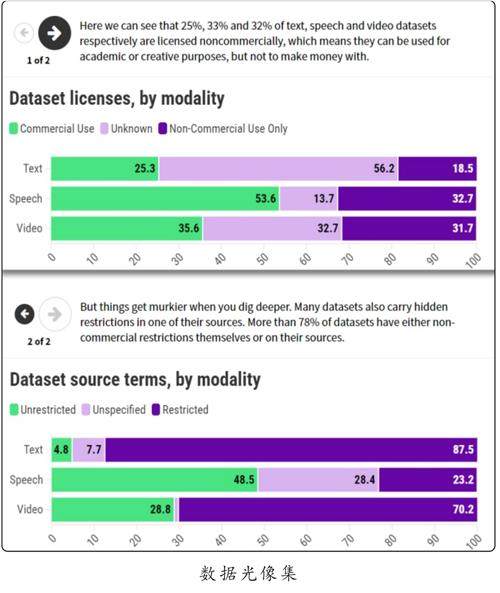
朗普雷补充道,这也让开发者几乎不可能完全确保他们的模型没有使用受版权保护的数据进行训练。
近年来,像OpenAI和谷歌这样的公司与出版商、Reddit等主要论坛以及社交媒体平台达成了独家数据共享协议。这种做法进一步巩固了它们的权力。
“这些独家合同实际上将互联网划分为谁能访问和谁不能访问的不同区域。”朗普雷指出。
这种趋势对能够负担此类协议的大型人工智能公司有利,但对研究人员、非营利组织和小型公司则构成了不利。这些较小的参与者将难以获得必要的数据,而大型公司不仅能签订独家协议,还拥有最强大的资源用于抓取数据集。
“这是我们在开放网络上前所未见的新一波非对称性访问。”郎普雷说道。

西方与其他地区的差距
用于训练人工智能模型的数据也存在严重的地域偏倚。研究人员分析发现,超过90%的数据集来自欧洲和北美,而来自非洲的数据不足4%。
胡克指出:“这些数据集仅反映了我们世界和文化的一部分,却完全忽视了其他地区。
训练数据中英语的主导地位部分可以用互联网的现状来解释。人工智能公司Hugging Face的首席伦理学家迦达·皮斯蒂利(并未参与此次研究)表示,互联网上超过90%的内容是英语,而地球上许多地区的互联网连接非常差,甚至没有互联网。她补充说,创建其他语言的数据集并将其他文化纳入考虑需要有意识的规划和大量的工作。
这种数据集的西方倾向在多模态模型中表现得尤为明显。胡克举例说,当一个人工智能模型被提示生成婚礼的场景和声音时,它可能只能呈现出西方婚礼的样子,因为它的训练数据仅限于此。
这种情况强化了偏见,可能导致人工智能模型推动一种以美国为中心的世界观,从而抹杀其他语言和文化的存在。
胡克指出:“我们在全球范围内使用这些模型,但模型所能看见的世界与看不见的世界之间存在巨大差距。”



