



AI大模型混战,中国云服务准备好了吗?
成本激增,算力抢滩难度颇高
随着ChatGPT引爆的人工智能大模型混战开打,算力之争也成为了各大头部企业争夺下一个“时代风口”的红海。所谓的人工智能大模型,也就是“大算力+强算法”结合的产物,通常是在大规模无标注数据上进行训练,学习出一种特征和规则,当需要具体的应用方向时,再将大模型进行微调,比如在特定任务上,进一步采用小规模有标注数据进行二次训练,当然,也可以不进行微调就直接参与多个应用场景。
在这个过程中不难发现,算力是打造大模型生态的必备基础,一个优秀的算力底座在大模型的训练和推理上具备效率优势,而平台是大模型和算力之间的“桥梁”,可针对不同的模型和硬件实现资源的合理分配,达到软硬件的最优组合,从而大幅提升训练模型的效率。根据IDC的数据显示,国家计算力指数与GDP/数字经济的走势呈现出了显著的正相关,十五个重点国家的计算力指数平均每提高1点,国家的数字经济和GDP将分别增长3.5‰和1.8‰,预计该趋势在2021-2025年将继续保持,所以,算力优势对经济的拉动作用将变得更加显著。
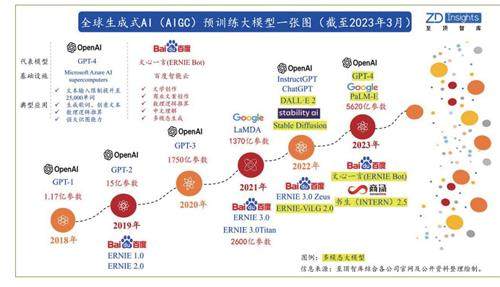
更重要的是,随着半导体短沟道效应以及量子隧穿效应带来的漏电、发热等问题愈发严重,摩尔定律已日趋放缓接近失效,人工智能训练算力需求增长与摩尔定律出现了严重的不匹配现象,这也将推动对算力基础设施需求的快速提升,而庞大的数据量以及算力决定了人工智能产业一定是典型的重资金产业:以GPT-3模型消耗的算力3640pfs-day为例,若按照单个500petaflops算力中心项目总投资约30亿元来计算,若想要保证ChatGPT的正常运行,则至少需要投入7~8个数据中心,所产生的总成本超过200亿元。

登录后获取阅读权限
去登录
本文刊登于《电脑报》2023年18期
龙源期刊网正版版权

更多文章来自

订阅