





摘要:为提高非法出入境笔录信息提取方面的命名实体识别能力,提出了一种融合语言模型的非法出入境笔录信息提取模型。该模型首先利用BERT模型对输入序列中的单词进行编码,得到每个单词的向量表示,然后将这些向量输入到BiLSTM网络中,利用LSTM网络时输入序列进行建模,学习输入序列中的上下文信息和语法结构等。最后,通过一个CRF层对BiLSTM网络的输出进行标注.从而得到最终的输出序列。实验结果表明,该模型能较好地应用于非法出入境笔录文本提取的任务。在与广西边防检查总站的合作项目里,最终将该模型应用于实际生产工作中,为边检警方的笔录提取工作提供便利。
关键词:非法出入境笔录文本;命名实体识别;BERT预训练语言模型;BiLSTM;CRF
中图法分类号:TP391 文献标识码:A
1 引言
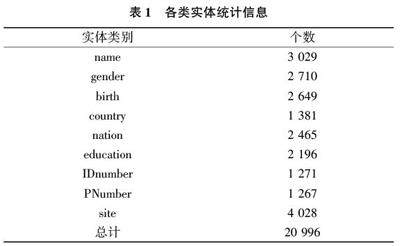
广西地处西南边陲,与越南毗邻,是中国对外开放的“桥头堡”,且拥有多个国家级和省级的对外开放口岸。近年来,越南和广西之间的交流日益频繁,但大规模、高频次的跨境流动人口中夹杂大量非法劳工,相关部门在对非法入境人员进行立案时,必须对被收容人的姓名、性别、国籍、民族、户籍、学历、身份证、手机等多项个人信息做详细的记录,而传统的人工采集方式需要消耗大量人力物力,且效率低下。为解决上述问题,本文通过广西出入境边防检查总站提供的原始笔录数据构建非法出入境笔录文本的命名实体识别语料库,提出了基于预训练模型的非法出入境笔录信息提取模型,并取得了较好的效果。
2 相关工作
1996 年,R. Grishman 和B. Sundheim 在MessageUnderstanding Conference(MUC⁃6) 上提出了“命名实体”的概念,该概念被广泛应用于自然语言处理领域[1] 。早期的命名实体识别主要依赖于规则和词典等手动构建的模板,与被识别的文档进行匹配以抽取实体。之后,基于特征工程和机器学习的方法成为主流,常用的方法包括最大熵[2] 、隐马尔可夫模型[3] 、支持向量机[4] 和条件随机场[5] 等。近年来,命名实体识别中出现了越来越多的神经网络模型[6] ,例如LSTM 模型[7] ,在LSTM 的基础上,研究人员引入条件随机场来增强模型的约束条件,预训练模型也逐渐被广泛应用于命名实体识别领域,提高了中文实体识别的效果。
国内外对于非法出入境笔录信息的命名实体研究较少,且可用的数据集稀缺,该领域的信息抽取问题亟待解决,主要包括:(1)基于机器学习的实体识别方法对人工特征依赖验证,难以捕获长距离上下文信息;(2)目前专门针对笔录信息提取领域的命名实体识别研究还十分稀少,也未构建相应的语料库;(3)笔录信息中常包含特征相似的实体,如越南身份证号码和越南手机号码均为数字组成,且位数相同,对于存在相似特征的实体,会增加实体提取的难度。
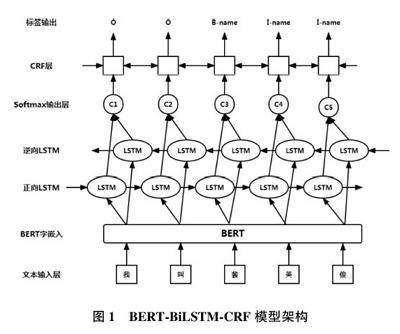
3 BERT⁃BiLSTM⁃CRF 模型
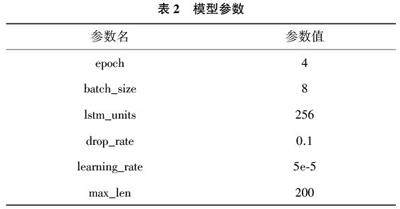
本文将非法出入境笔录文本作为原始语料,分段清洗后并对其进行标注。这些标注数据被输入到BERT⁃BiLSTM⁃CRF 模型中进行实体识别。


