



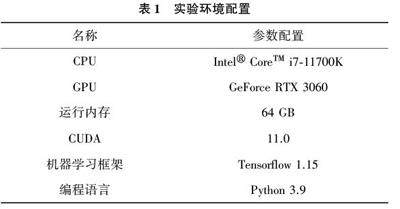
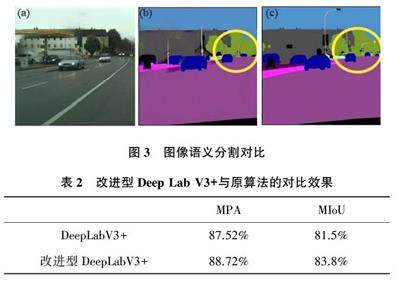
摘要:深度學习在图像语义分割方面有着广泛的应用,能够提高计算机对图像的理解和识别能力,同时在自动驾驶、医学影像等领域具有重要作用。然而,其现有算法还存在一些缺陷,如预测结果不连续、精度不高等。因此,文章基于深度学习技术以DccpLab V3+框架为研究对象,探究其基本原理和核心架构.并基于Xccption提出一种改进型DccpLab V3+框架,以解决预测结果不连续、下采样导致特征图信息丢失等问题,从而提高分割的精度。该研究使用Cityscapcs数据集进行实验验证.并将改进的框架与初始的DccpLab V3+框架进行了比较。实验结果表明,该方法在平均交并比方面表现更优,提高了2.82%的分割精度。
关键词:DccpLab;Xccption;语义分割;Cityscapcs
中图法分类号:TP391 文献标识码:A
1 概述
随着海量图像数据的不断涌现,计算机视觉成为当前计算机专业研究的热门方向。目前,计算机视觉研究的主要研究领域包括图像分类[1] 、目标检测与识别[2] 以及语义分割[3] 等。其中,语义分割是指对原图像中每个像素点所属的类别概率进行预测,并将不同类别的像素点用不同颜色进行标识。语义分割在自动驾驶领域中可以实现对道路场景的自动识别,在医学影像中可以辅助医生的决策和诊断,在农机自动化中能够实现农业设备的路径识别导航等。
2014 年,谷歌团队提出了DeepLab 系列模型,在此之前,深度卷积神经网络已被广泛应用于目标检测和图像分类等研究领域。但是,深度卷积神经网络在图像语义分割领域有着难以克服的缺陷。比如,卷积神经网络中的池化层在进行下采样时会导致图像的分辨率降低、使图像中的空间位置信息偏差较大等。
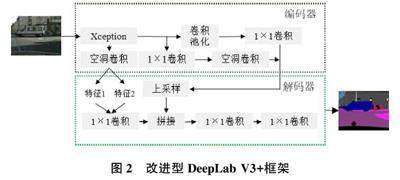
为解决这些问题,本文研究了基于DeepLab V3+框架的图像语义分割算法并提出了改进型框架。首先,本文探究了DeepLab V3+框架的基本原理和模型结构,然后,将Xception 作为DeepLab V3+框架的图像特征提取网络,最后使用Cityscapes 街景数据集进行了模型验证。实验结果表明,改进后的DeepLab V3+框架比原算法在分割精度MIoU 方面提高了2.82%。
2 基于DeepLab 模型的图像语义分割方法
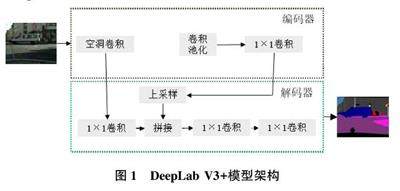
2.1 DeepLabV3+模型结构
DeepLab V3+模型是在DeepLab V3 模型的基础上进行优化而来的,该模型结合了编码⁃解码型算法多方面的优势。DeepLab V3+模型中的编码器和解码器2 个模块使它能够更好地平衡精度和时间。


