




全球生成式AI领域已经形成两大寡头,一家是创造了ChatGPT的OpenAI,另一家是Anthropic。
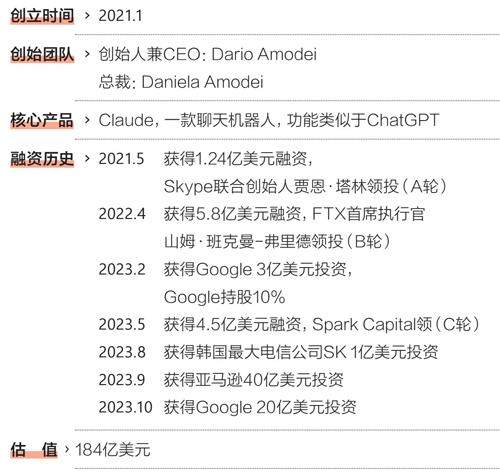
Anthropic的创始团队也是GPT系列产品的早期开发者。2020年6月,OpenAI发布第三代大语言模型(LargeLanguageModel,LLM)GPT-3。半年之后,研究副总裁达里奥·阿莫迪(DarioAmodei)和安全政策副总裁丹妮拉·阿莫迪(DanielaAmodei)决定离职,创立一家与OpenAI有不一样价值观的人工智能公司—Anthropic。
他们有一个很明确的目标,就是构建一套“可靠、可解释、可控的‘以人类(利益)为中心’”的人工智能系统。这些关键词听起来都很熟悉?没错,它们都曾是OpenAI宣称的愿景。但2019年之后,尤其在接受了微软的100亿美元投资之后,愿景与现实起了冲突,商业和第一个抵达通用人工智能(ArtificialGenenralIntelligence,AGI)的野心取代“对人类安全”成了OpenAI更重要的东西。
达里奥和丹妮拉是亲兄妹,2021年,他们带着OpenAI的愿景和OpenAI另外5名员工一起离开了,5名员工中的TomBrown曾领导GPT-3模型开发。新公司的名称“Anthropic”的意思是,与人类有关的。听起来,这是一个代表人类利益而不是AI利益的公司。
不过,要挑战OpenAI这样技术和资金实力俱佳的领先者(OpenAI早在2015年就创立了,ChatGPT所基于的GPT-3.5也在Anthropic创立之时就差不多训练好了),困难程度不亚于最初创立OpenAI的那批人立志要打破Google的AI垄断。但是当OpenAI变得不再Open,并且,用达里奥和丹妮拉的话说,变得不再“以人类为中心”,技术权柄被新的理想主义者夺走的故事就有可能再次上演。
生成式AI的悖论:追求有用?还是无害?
无害和有用在生成式AI身上是矛盾的。一个常常用“我不知道”回答问题的AI是无害的,但同時也是无用的。你可能已经碰到过这种状况,当你问出一些有争议的问题时,AI助手经常拒绝回答—像人一样。如果你多次追问,还会将其逼入困境,接下来的对话中,这位AI助手的回应可能都是回避性的—像经历过大量攻击性语言后产生回避型人格的人一样。
2022年4月,ChatGPT发布前,Anthropic就发表论文(31人署名)讨论了有用和无害之间存在的显著紧张关系。对其产生原因,Anthropic认为“这是因为我们的众包工作者对有害输入的回应是回避性的”。
在Anthropic之前,生成式AI(包括GPT)在训练AI与人类价值观保持一致(alignment,就是业内人所说的“对齐”)时,普遍采用的训练方式叫作“基于人类反馈的强化学习”(ReinforcementLearningfromHumanFeedback,RLHF)。训练过程中,人工智能公司会招募成千上万个人类训练师,对AI生成的答案做品质排序,由此保证那些符合人类价值观的答案获得更高排名、有更大可能性被再次生成,不符合人类价值观的答案则被排在后面,越来越不可能再次生成。
Anthropic
这样人为调教的好处显而易见,AI学会了礼貌、不会冲撞人类,但弊端也难以避免,尤其当向AI提供人类反馈的那些训练师刚好是回避型人格、属于高敏感人群。人群中总有这样的人,而人工智能公司在将其“基于人类反馈的强化学习”工作外包时,基本不会对外包人群做性格测试,甚至它们第一步收集到的训练数据中,也极少包含“积极处理有害请求”的那类数据。没错,人类自身本来就缺乏这种文化。
对这种“向人类偏好对齐造成的能力损耗”,业内人士有个戏称:对齐税。
Anthropic不愿掉入先行者ChatGPT遭遇的陷阱,它的目标是培养一个“不回避、有用且无害”的助手。2022年12月,ChatGPT刚发布不久,Anthropic又发表了(51人署名,没错,半年之内,Anthropic就壮大了)一篇论文,提出新的AI价值观训练方法—基于AI反馈的强化学习(ReinforcementLearningfromAIFeedback,RLAIF)。与GPT等使用人类为模型生成的答案打分、排序不同,Anthropic用另一个AI为生成式模型生成的答案打分、排序,这个AI叫作“宪法AI”(ConstitutionalAI,CAI)。


